前言
GCD的队列是GCD源码分析系列中的重点
队列的定义
dispatch_queue_s是一个结构体,定义如下:1
2
3
4
5struct dispatch_queue_s {
DISPATCH_STRUCT_HEADER(dispatch_queue_s, dispatch_queue_vtable_s);
DISPATCH_QUEUE_HEADER;
char dq_label[DISPATCH_QUEUE_MIN_LABEL_SIZE]; // must be last
};
可以看到结构体里面包含两个宏和一个dq_label
DISPATCH_STRUCT_HEADER
1 |
|
在GCD中,很多结构体的定义基本上都会调用DISPATCH_STRUCT_HEADER,并把结构体的名字作为第一个宏参数x传递进去,而第二个宏参数y通常是dispatch_queue_vtable_s。struct x *volatile do_next,x参数仅仅会影响do_next的指针类型,可以理解为将来要进行链表操作。很显然,在队列的定义中,这行展开为:1
struct dispatch_queue_s *volatile do_next;
而第二个参数y也只是会影响到do_vtable指针的类型,这里展开为:1
const struct dispatch_queue_vtable_s *do_vtable;
dispatch_queue_vtable_s这个结构体内包含了这个dispatch_object_s
或者其子类的操作函数,而且针对这些操作函数,定义了相对简短的宏,方便调用1
2
3
4
5
6unsigned long const do_type; \ // 数据的具体类型
const char *const do_kind; \ // 数据的类型描述字符串
size_t (*const do_debug)(struct x *, char *, size_t); \ // 用来获取调试时需要的变量信息
struct dispatch_queue_s *(*const do_invoke)(struct x *);\ // 唤醒队列的方法,全局队列和主队列此项为NULL
bool (*const do_probe)(struct x *); \ // 用于检测传入对象中的一些值是否满足条件
void (*const do_dispose)(struct x *) // 销毁队列的方法,通常内部会调用 这个对象的 finalizer 函数
DISPATCH_QUEUE_HEADER
1 |
|
dq_label
dq_label代表队列的名字,且最长的长度不能超过DISPATCH_QUEUE_MIN_LABEL_SIZE = 64
队列的获取
GCD队列的获取通常有以下几种方式:
1、主队列:dispatch_get_main_queue
1 |
可以看到dispatch_get_main_queue实际上是一个宏,它返回的是结构体_dispatch_main_q的地址1
2
3
4
5
6
7
8
9
10
11
12struct dispatch_queue_s _dispatch_main_q = {
.do_vtable = &_dispatch_queue_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_targetq = &_dispatch_root_queues[DISPATCH_ROOT_QUEUE_COUNT / 2],
.dq_label = "com.apple.main-thread",
.dq_running = 1,
.dq_width = 1,
.dq_serialnum = 1,
};
do_vtable
看看主队列的函数指针do_vtable的指向:_dispatch_queue_vtable1
2
3
4
5
6
7
8static const struct dispatch_queue_vtable_s _dispatch_queue_vtable = {
.do_type = DISPATCH_QUEUE_TYPE,
.do_kind = "queue",
.do_dispose = _dispatch_queue_dispose,
.do_invoke = (void *)dummy_function_r0,
.do_probe = (void *)dummy_function_r0,
.do_debug = dispatch_queue_debug,
};
do_ref_cnt && do_xref_cnt
这两个值和GCD对象的内存管理有关,只有两个值同时为0,GCD对象才能被释放,主队列的这两个成员的值都为DISPATCH_OBJECT_GLOBAL_REFCNT:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
void _dispatch_retain(dispatch_object_t dou)
{
if (dou._do->do_ref_cnt == DISPATCH_OBJECT_GLOBAL_REFCNT) {
return; // global object
}
...
}
void dispatch_release(dispatch_object_t dou)
{
typeof(dou._do->do_xref_cnt) oldval;
if (dou._do->do_xref_cnt == DISPATCH_OBJECT_GLOBAL_REFCNT) {
return;
}
...
从_dispatch_retain和dispatch_release函数中可以看出,主队列的生命周期是伴随着应用的,不会受retain和release的影响
do_targetq
目标队列,通常非全局队列(例如mgr_queue),需要压入到glablalQueue中来处理,因此需要指明target_queue1
1 | .do_targetq = &_dispatch_root_queues[DISPATCH_ROOT_QUEUE_COUNT / 2], |
即为”com.apple.root.default-overcommit-priority”这个全局队列
管理队列:_dispatch_mgr_q
注:这个队列是GCD内部使用的,不对外公开1
2
3
4
5
6
7
8
9
10
11struct dispatch_queue_s _dispatch_mgr_q = {
.do_vtable = &_dispatch_queue_mgr_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_targetq = &_dispatch_root_queues[DISPATCH_ROOT_QUEUE_COUNT - 1],
.dq_label = "com.apple.libdispatch-manager",
.dq_width = 1,
.dq_serialnum = 2,
};
do_vtable
看看管理队列的函数指针do_vtable的指向:_dispatch_queue_mgr_vtable1
2
3
4
5
6
7static const struct dispatch_queue_vtable_s _dispatch_queue_mgr_vtable = {
.do_type = DISPATCH_QUEUE_MGR_TYPE,
.do_kind = "mgr-queue",
.do_invoke = _dispatch_mgr_invoke,
.do_debug = dispatch_queue_debug,
.do_probe = _dispatch_mgr_wakeup,
};
do_ref_cnt && do_xref_cnt
可以参考主队列
do_targetq
即为”com.apple.root.high-overcommit-priority”这个全局队列
全局队列:dispatch_get_global_queue
1 | enum { |
我们当前分析的libdispatch定义了6个全局队列(最新的版本有8个全局队列)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74static struct dispatch_queue_s _dispatch_root_queues[] = {
{
.do_vtable = &_dispatch_queue_root_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_ctxt = &_dispatch_root_queue_contexts[0],
.dq_label = "com.apple.root.low-priority",
.dq_running = 2,
.dq_width = UINT32_MAX,
.dq_serialnum = 4,
},
{
.do_vtable = &_dispatch_queue_root_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_ctxt = &_dispatch_root_queue_contexts[1],
.dq_label = "com.apple.root.low-overcommit-priority",
.dq_running = 2,
.dq_width = UINT32_MAX,
.dq_serialnum = 5,
},
{
.do_vtable = &_dispatch_queue_root_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_ctxt = &_dispatch_root_queue_contexts[2],
.dq_label = "com.apple.root.default-priority",
.dq_running = 2,
.dq_width = UINT32_MAX,
.dq_serialnum = 6,
},
{
.do_vtable = &_dispatch_queue_root_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_ctxt = &_dispatch_root_queue_contexts[3],
.dq_label = "com.apple.root.default-overcommit-priority",
.dq_running = 2,
.dq_width = UINT32_MAX,
.dq_serialnum = 7,
},
{
.do_vtable = &_dispatch_queue_root_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_ctxt = &_dispatch_root_queue_contexts[4],
.dq_label = "com.apple.root.high-priority",
.dq_running = 2,
.dq_width = UINT32_MAX,
.dq_serialnum = 8,
},
{
.do_vtable = &_dispatch_queue_root_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_ctxt = &_dispatch_root_queue_contexts[5],
.dq_label = "com.apple.root.high-overcommit-priority",
.dq_running = 2,
.dq_width = UINT32_MAX,
.dq_serialnum = 9,
},
};
do_vtable
看看全局队列的函数指针do_vtable的指向:_dispatch_queue_root_vtable1
2
3
4
5
6static const struct dispatch_queue_vtable_s _dispatch_queue_root_vtable = {
.do_type = DISPATCH_QUEUE_GLOBAL_TYPE,
.do_kind = "global-queue",
.do_debug = dispatch_queue_debug,
.do_probe = _dispatch_queue_wakeup_global,
};
do_ref_cnt && do_xref_cnt
可以参考主队类
do_ctxt
注意全局队列有一个do_ctxt,它是上下文,是我们要传递的参数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static struct dispatch_root_queue_context_s _dispatch_root_queue_contexts[] = {
{
.dgq_thread_mediator = &_dispatch_thread_mediator[0],
.dgq_thread_pool_size = MAX_THREAD_COUNT,
},
{
.dgq_thread_mediator = &_dispatch_thread_mediator[1],
.dgq_thread_pool_size = MAX_THREAD_COUNT,
},
{
.dgq_thread_mediator = &_dispatch_thread_mediator[2],
.dgq_thread_pool_size = MAX_THREAD_COUNT,
},
{
.dgq_thread_mediator = &_dispatch_thread_mediator[3],
.dgq_thread_pool_size = MAX_THREAD_COUNT,
},
{
.dgq_thread_mediator = &_dispatch_thread_mediator[4],
.dgq_thread_pool_size = MAX_THREAD_COUNT,
},
{
.dgq_thread_mediator = &_dispatch_thread_mediator[5],
.dgq_thread_pool_size = MAX_THREAD_COUNT,
},
};
其中的_dispatch_thread_mediator定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32static struct dispatch_semaphore_s _dispatch_thread_mediator[] = {
{
.do_vtable = &_dispatch_semaphore_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
},
{
.do_vtable = &_dispatch_semaphore_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
},
{
.do_vtable = &_dispatch_semaphore_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
},
{
.do_vtable = &_dispatch_semaphore_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
},
{
.do_vtable = &_dispatch_semaphore_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
},
{
.do_vtable = &_dispatch_semaphore_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
},
};
自定义队列
1 | dispatch_queue_t dispatch_queue_create(const char *label, dispatch_queue_attr_t attr) |
_dispatch_queue_init
来看下内联函数_dispatch_queue_init的实现1
2
3
4
5
6
7
8
9
10
11inline void _dispatch_queue_init(dispatch_queue_t dq)
{
dq->do_vtable = &_dispatch_queue_vtable;
dq->do_next = DISPATCH_OBJECT_LISTLESS;
dq->do_ref_cnt = 1;
dq->do_xref_cnt = 1;
dq->do_targetq = _dispatch_get_root_queue(0, true);
dq->dq_running = 0;
dq->dq_width = 1;
dq->dq_serialnum = dispatch_atomic_inc(&_dispatch_queue_serial_numbers) - 1;
}
通过前面的代码可以发现,全局队列的并发数dq_width均为UINT32_MAX,而这里_dispatch_queue_init中的dq_width为1,说明这是一个串行队列的默认设置。
另外dq->do_targetq = _dispatch_get_root_queue(0, true),它涉及到GCD队列与block 的一个重要模型,target_queue。向任何队列中提交的 block,都会被放到它的目标队列中执行,而普通串行队列的目标队列就是一个支持 overcommit 的全局队列,全局队列的底层则是一个线程池。
引用苹果的一张经典图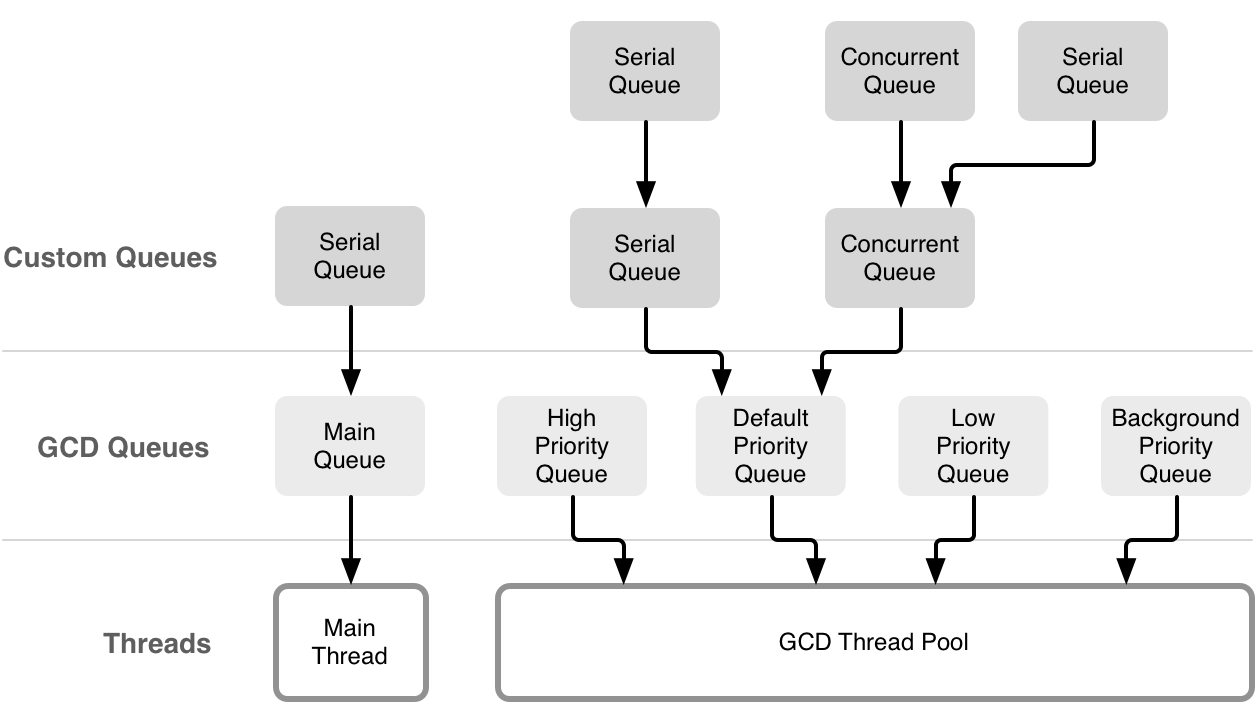
其他的属性基本上可以参考前面的信息,这里着重理解下dq_serialnum:1
static unsigned long _dispatch_queue_serial_numbers = 10;
1 | // skip zero |
可以看到,0被跳过,3未使用,1用于主队列,2用于管理队列,4~9用于全局队列。自定义队列从10开始,每次自定义一个队列时,都会先原子操作_dispatch_queue_serial_numbers变量,然后减1,这样保证了每个自定义队列的dq_serialnum的唯一性。
dispatch_queue_attr_t特殊处理
如果在自定义队列时,传递了attr参数,那么表示支持overcommit,带有overcommit 的队列表示每当有任务提交时,系统都会新开一个线程处理,这样就不会造成某个线程过载。
同时如果finalizer_func == _dispatch_call_block_and_release2需要对dq_finalizer_ctxt进行retain1
2
3
4
5
6void _dispatch_call_block_and_release2(void *block, void *ctxt)
{
void (^b)(void*) = block;
b(ctxt);
Block_release(b);
}
常用API解析
dispatch_async
1 | void dispatch_async(dispatch_queue_t dq, void (^work)(void)) |
dispatch_async主要将参数进行了处理,然后去调用dispatch_async_f`
- 1、
_dispatch_Block_copy在堆上创建传入block的拷贝,或者增加引用计数,这样就保证了block在执行之前不会被销毁- 2
_dispatch_call_block_and_release的定义如下,顾名思义,调用block,然后将block销毁
1 | void _dispatch_call_block_and_release(void *block) |
dispatch_async_f
接下来分析一下dispatch_async_f的实现1
2
3
4
5
6
7
8
9
10
11void dispatch_async_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func)
{
dispatch_continuation_t dc = fastpath(_dispatch_continuation_alloc_cacheonly());
if (!dc) {
return _dispatch_async_f_slow(dq, ctxt, func);
}
dc->do_vtable = (void *)DISPATCH_OBJ_ASYNC_BIT;
dc->dc_func = func;
dc->dc_ctxt = ctxt;
_dispatch_queue_push(dq, dc);
}
- 1、我们首先来看下
_dispatch_continuation_alloc_cacheonly,它的目的就是从线程的TLS(线程的私有存储,线程都是有自己的私有存储的,这些私有存储不会被其他线程所使用)中提取出一个dispatch_continuation_t结构
1 | static inline dispatch_continuation_t _dispatch_continuation_alloc_cacheonly(void) |
- 2、如果线程中的TLS不存在
dispatch_continuation_t结构的数据,则走_dispatch_async_f_slow() 函数。- 3、如果dc不为空,设置其do_vtable为DISPATCH_OBJ_ASYNC_BIT(主要用于区分类型),把传入的block传给dc的dc_ctxt作为上下文,最后将dc的dc_func设置为_dispatch_call_block_and_release,最后调用_dispatch_queue_push进行入队操作
DISPATCH_OBJ_ASYNC_BIT是一个宏定义,是为了区分async、group和barrier。
1 |
继续往下分析_dispatch_async_f_slow1
2
3
4
5
6
7
8
9
10
11DISPATCH_NOINLINE static void _dispatch_async_f_slow(dispatch_queue_t dq, void *context, dispatch_function_t func)
{
dispatch_continuation_t dc = fastpath(_dispatch_continuation_alloc_from_heap());
dc->do_vtable = (void *)DISPATCH_OBJ_ASYNC_BIT;
dc->dc_func = func;
dc->dc_ctxt = context;
// 往dq这个队列中压入了一个续体dc
_dispatch_queue_push(dq, dc);
}
1 | dispatch_continuation_t _dispatch_continuation_alloc_from_heap(void) |
从堆上获取dispatch_continuation_t之后,设置dc的成员,跟前面一致。之后同样走到了_dispatch_queue_push函数
_dispatch_queue_push
继续往下分析_dispatch_queue_push1
_dispatch_queue_push是一个宏,实际上是调用了_dispatch_queue_push_list
_dispatch_queue_push_list
1 | static inline void |
_dispatch_queue_push_list 函数是 inline函数,说明这个函数会调用很频繁,inline 通常用在内核中,效率很高,但生成的二进制文件会变大,典型的空间换时间。
1、 如果队列不为空,那么直接将该dc放到队尾,并重定向dq->dq_items_tail,因为队列前面还有任务,所以此时把dc插入到队尾就OK了
这里解释一下为什么会重定向:
- 根据
dispatch_atomic_xchg的定义“将p设为n并返回p操作之前的值”,dispatch_atomic_xchg(&dq->dq_items_tail, tail)这行代码的含义等同于:dq->dq_items_tail = tail,重定向了队尾指针- prev是原先的队尾元素,prev->do_next = head则把tail结点放到了队尾。
2、如果队列为空,则调用
_dispatch_queue_push_list_slow:
2
3
4
5
6
7
{
_dispatch_retain(dq);
dq->dq_items_head = obj;
_dispatch_wakeup(dq);
_dispatch_release(dq);
}
_dispatch_queue_push_list_slow直接将dq->dq_items_head设置为dc,然后调用_dispatch_wakeup唤醒这个队列。这里直接执行_dispatch_wakeup的原因是此时队列为空,没有任务在执行,处于休眠状态,所以需要唤醒。
_dispatch_wakeup
接下来分析一下如何唤醒一个队列:这里的dou指队列1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30dispatch_queue_t _dispatch_wakeup(dispatch_object_t dou)
{
dispatch_queue_t tq;
if (slowpath(DISPATCH_OBJECT_SUSPENDED(dou._do))) {
return NULL;
}
// 全局队列的dx_probe指向了_dispatch_queue_wakeup_global,这里走唤醒逻辑
// 如果唤醒失败,且队尾指针为空,则返回NULL
if (!dx_probe(dou._do) && !dou._dq->dq_items_tail) {
return NULL;
}
if (!_dispatch_trylock(dou._do)) {
if (dou._dq == &_dispatch_main_q) {
//传入主队列,会进入到 _dispatch_queue_wakeup_main() 函数中
_dispatch_queue_wakeup_main();
}
return NULL;
}
// 如果既不是全局队列,也不是主队列,则找到该队列的目标队列do_targetq,将续体压入目标队列,继续走_dispatch_queue_push逻辑
_dispatch_retain(dou._do);
tq = dou._do->do_targetq;
_dispatch_queue_push(tq, dou._do);
return tq; // libdispatch doesn't need this, but the Instrument DTrace probe does
}
- 1、如果是主队列,则直接调用_dispatch_queue_wakeup_main
1 | void _dispatch_queue_wakeup_main(void) |
2、如果是全局队列,会进入到全局队列的dx_probe指向的函数
_dispatch_queue_wakeup_global中:
在这里面我们就真正的接触到pthread了
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
{
static dispatch_once_t pred;
struct dispatch_root_queue_context_s *qc = dq->do_ctxt;
pthread_workitem_handle_t wh;
unsigned int gen_cnt;
pthread_t pthr;
int r, t_count;
if (!dq->dq_items_tail) {
return false;
}
_dispatch_safe_fork = false;
dispatch_debug_queue(dq, __PRETTY_FUNCTION__);
// 全局队列的检测,初始化和配置环境(只调用1次)
dispatch_once_f(&pred, NULL, _dispatch_root_queues_init);
// 如果队列的dgq_kworkqueue不为空,则从
if (qc->dgq_kworkqueue) {
if (dispatch_atomic_cmpxchg(&qc->dgq_pending, 0, 1)) {
_dispatch_debug("requesting new worker thread");
r = pthread_workqueue_additem_np(qc->dgq_kworkqueue, _dispatch_worker_thread2, dq, &wh, &gen_cnt);
dispatch_assume_zero(r);
} else {
_dispatch_debug("work thread request still pending on global queue: %p", dq);
}
goto out;
}
// 发送一个信号量,这是一种线程保活的方法
if (dispatch_semaphore_signal(qc->dgq_thread_mediator)) {
goto out;
}
// 检测线程池可用的大小,如果还有,则线程池减1
do {
t_count = qc->dgq_thread_pool_size;
if (!t_count) {
_dispatch_debug("The thread pool is full: %p", dq);
goto out;
}
} while (!dispatch_atomic_cmpxchg(&qc->dgq_thread_pool_size, t_count, t_count - 1));
// 使用pthread 库创建一个线程,线程的入口是_dispatch_worker_thread
while ((r = pthread_create(&pthr, NULL, _dispatch_worker_thread, dq))) {
if (r != EAGAIN) {
dispatch_assume_zero(r);
}
sleep(1);
}
// 调用pthread_detach,主线程与子线程分离,子线程结束后,资源自动回收
r = pthread_detach(pthr);
dispatch_assume_zero(r);
out:
return false;
}1、如果队列上下文中的
dgq_kworkqueue存在,则调用pthread_workqueue_additem_np函数,该函数使用workq_kernreturn系统调用,通知workqueue增加应当执行的项目。根据该通知,XNU内核基于系统状态判断是否要生成线程,如果是overcommit优先级的队列,workqueue则始终生成线程,之后线程执行_dispatch_worker_thread2函数。2、反之,如果
dgq_kworkqueue不存在,则调用pthread_create函数直接启动一个线程,执行_dispatch_worker_thread函数,但是这个函数中仍然调用到了_dispatch_worker_thread2,和第1条殊途同归。
_dispatch_worker_thread
1 | void *_dispatch_worker_thread(void *context) |
函数前面主要是设置新线程的信号掩码,真正的任务调度在_dispatch_worker_thread2里面,而我们也可以看到,这个任务调度结束后,这个线程在等待一个信号量,而等待的信号量就是前面dispatch_queue_wakeup_global里面的信号量,为什么要这样做?这样做的原因是不要频繁开启新线程,如果有一个新线程完成所有任务了,这个线程就要结束了,但这里并不是这样,而是等待一个信号量,大约等待65秒,如果65秒内接收到新的信号量(表示有新的任务),这个线程就会去继续执行加进来的任务,而不是重新开启新线程,65秒后没接收到信号量,则退出这个线程,销毁这个线程
_dispatch_worker_thread2
前面提到的两种方式实际上最终都调用到了_dispatch_worker_thread2函数,可见核心的执行逻辑都在这里,需要格外关注:
1 | void _dispatch_worker_thread2(void *context) |
这个函数里面进行任务的调度,两个函数很重要,
- 1、一个是
_dispatch_queue_concurrent_drain_one,用来取出队列的一个内容;- 2、另一个是
_dispatch_continuation_pop函数,用来对取出的内容进行处理;
_dispatch_queue_concurrent_drain_one
先来分析下_dispatch_queue_concurrent_drain_one
1 | struct dispatch_object_s * |
_dispatch_continuation_pop
接下来分析一下_dispatch_continuation_pop
1 | static inline void _dispatch_continuation_pop(dispatch_object_t dou) |
从上面的函数中可以发现,压入队列的不仅是续体任务,还有可能是队列。如果是队列,直接执行了_dispatch_queue_invoke,否则执行dc->dc_func(dc->dc_ctxt)
接下来分析一下_dispatch_queue_invoke的执行过程,即pop出来的队列是如何被执行的
1 | DISPATCH_NOINLINE void _dispatch_queue_invoke(dispatch_queue_t dq) |
如果是直接触发,即直接调用dx_invoke,那么会返回NULL
流程整理
dispatch_async 的实现比较复杂,主要是因为其中的数据结构较多,分支流程控制比较复杂。但思路其实很简单,用链表保存所有提交的 block,然后在底层线程池中,依次取出 block 并执行,具体的函数调用流程如下图:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18dispatch_async
└──_dispatch_async_f_slow
└──_dispatch_queue_push
└──_dispatch_queue_push_list
└──_dispatch_queue_push_list_slow
└──_dispatch_wakeup
└──_dispatch_queue_wakeup_main
└──_dispatch_send_wakeup_main_thread
└──_dispatch_queue_wakeup_global
└──pthread_workqueue_additem_np
└──_dispatch_worker_thread2
└──pthread_create
└──_dispatch_worker_thread
└──_dispatch_worker_thread2
└──_dispatch_queue_concurrent_drain_one
└──_dispatch_continuation_pop
└──_dispatch_queue_invoke(queue)
└──dc->dc_func(dc->dc_ctxt)(continuation);
dispatch_sync
说完了dispatch_async,再来看下dispatch_sync。
1 | void dispatch_sync(dispatch_queue_t dq, void (^work)(void)) |
- 1、 如果是主队列,则调用_dispatch_sync_slow,可以看到,这个方法最终还是调用了
dispatch_sync_f。
1 | static void _dispatch_sync_slow(dispatch_queue_t dq, void (^work)(void)) |
- 2、否则,调用dispatch_sync_f:
1 | void dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func) |
- 3、如果是向一个串行队列压入同步任务,则调用dispatch_barrier_sync_f:
1 | void dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func) |
- 4、如果向一个并发队列中压入同步任务,如果队列不为空,或者挂起,或者有正在执行的任务,则调用
_dispatch_sync_f_slow,进行信号等待,否则直接调用_dispatch_wakeup唤醒队列执行任务
1 | static void _dispatch_sync_f_slow(dispatch_queue_t dq) |
流程整理
dispatch_sync同步方法的实现相对来说更简单,只需要将任务压入响应的队列,并用信号量做等待,具体调用栈如下:1
2
3
4
5dispatch_sync
└──_dispatch_sync_slow
└──dispatch_sync_f
└──dispatch_barrier_sync_f(串行队列压入同步任务)
└──_dispatch_sync_f_slow(并发队列中压进一个同步任务)
总结
队列的内容比较多,而且比较复杂,由于本人能力有限,难免有些地方理解不够到位,写的不够清晰,请多多指教。

